
This is a guest post written by my friend, Jeremy Kun! He’s the author of the popular blog Math ∩ Programming, your go-to site for learning about algorithms, machine learning, cryptography, and so much more.
There’s a deep connection in mathematics between a graph (a set of vertices and edges), and the algebraic properties of special matrices associated with that graph.
Here’s the simplest example of this phenomenon. Say you take an undirected graph 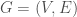
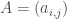
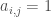
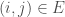
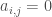

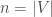
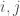
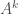
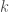
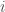


In this example, the cube of the adjacency matrix counts the number of length-3 walks (paths where you can repeat vertices/edges) between all pairs of nodes. So there is one walk from 5 to 3, and four walks from 1 to 4.
You can take this a step further and divide the
The area of math where you take a graph and do linear algebra on its adjacency matrix is called spectral graph theory. But as useful as the adjacency matrix is, there’s another matrix you can associate with a graph that receives tons of attention in spectral graph theory: the graph Laplacian.
There are many ways to motivate the graph Laplacian. If you’re a physicist, electrical engineering, or applied math whiz, you’ll recognize the Laplacian from partial differential equations and just discretize it in the natural way, but I won’t assume too much prior familiarity with that subject. In fact, if you’re not inclined to think about continuous systems of differential equations, you can still appreciate the graph Laplacian.
Here’s one way to motivate it. Let 

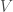
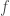
Definition: The graph gradient of 

An example of the graph gradient.
One way to think about the values of the gradient is that the derivative of
But unlike in discrete calculus, the graph gradient isn’t a very nice object. Specifically, the difference operator implies a direction on the edges, but there isn’t a natural way to pick one. We could just pick directions arbitrarily, but then some numerical properties of the gradient wouldn’t be well-defined. You could also fix your reference point as a single vertex, but then you only get directions on edges going “out of” that vertex.
However, one property that doesn’t depend on the choice of orientation is the (squared) Euclidean norm of the gradient, 
Another way to think of the squared Euclidean norm quantity is as a quadratic form, which is a polynomial in many variables where all the terms have degree 2. These polynomials can always be rewritten in a matrix form 

The matrix part of our particular squared-gradient quadratic form is called the graph Laplacian, and we even have a nice formula for it.
Definition: Let 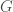
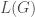
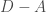
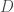


An example of the combinatorial graph laplacian
If you like the gradient idea from earlier, you should think of the graph Laplacian as a matrix that is encoded with the process of computing gradients and gradient-norms for arbitrary functions on 
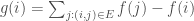
This should be motivating enough to study the Laplacian in detail. And it will pay off in a big way. The main insight to draw is that the eigenvalues and eigenvectors of the Laplacian provide useful, actionable information about the structure of the graph.
Fourier transforms, for comparison
A priori, one might wonder why you could hope to extract information from the eigenvectors and eigenvalues of the graph Laplacian, and so I’d like to just briefly mention that this is a direct analogue of the continuous case: Fourier analysis.
One abbreviated way to think about Fourier analysis is to start with the Laplace operator 

This is a linear map on the vector space of (at least) twice differentiable functions. And once you fall madly in love with linear algebra, you’re destined to ask what are the eigenvectors of

Where 



The same pattern works for the graph Laplacian, but for Fourier analysis it’s a teensy bit simpler in that the eigenvectors don’t depend on an arbitrary underlying graph (the “graph” is just 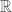
In fact, though we won’t discuss it in detail in this post, you can do Fourier analysis on graphs in exactly the same manner, and process functions on graphs as “signals,” performing low-pass filters and such. See this paper for more on that. A taste: once you write down the eigenvectors 
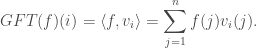
Here the “functions” are just vectors, so the inner product is the normal dot product. But rather than do Fourier analysis, let’s dive into a study of the eigenvalues and eigenvectors of the Laplacian.
Eigenvectors of the Laplacian
Earlier we defined the Laplacian to be 
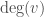
Definition: Let 


Let’s update our example from earlier:

The graph Laplacian (with truncated real-valued entries)
The quadratic form is also normalized now, and the normalization is weighted by vertex degree.

Some authors call this the normalized graph Laplacian. If you again write 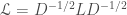
For instance, the simplest eigenvector of 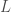

is an eigenvector of 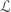
It also happens that the eigenvectors minimize the quadratic form 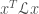

The next smallest eigenvalue, 
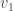
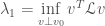
Theorem: 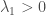
Proof sketch: If 



More significantly, 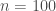

The growth rate of the second smallest eigenvalue as the density of the graph increases.
The right-most end of the graph is when all edges are present (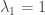
All of this tells us roughly that
Theorem (informal): Let
See Definition 1.1 of these notes for a concrete definition of the sparsest cut. But informally, it is the partition of the vertices into two parts that minimizes the ratio of edges crossing the cut over edges within each part of the cut. If the graph is disconnected (and 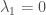
This is the inspiration for the sparsest cut algorithm, which was originally due (I believe) to Leighton-Rao and has a relatively complicated proof I won’t cover here. Instead, I implemented it in Python. Here’s a Github repository with the code in full (and all the diagrams used in this post). The core of the algorithm is the following (abbreviated) snippet. Note that it uses numpy for its eigenvalue solver.
def bestCut(graph):
laplacianMatrix = laplacian(graph, normalize=True) # defined elsewhere
n, m = laplacianMatrix.shape
eigenvalues, eigenvectors = numpy.linalg.eig(laplacianMatrix)
sortedIndices = eigenvalues.argsort()
eigenvectors = eigenvectors[:, sortedIndices]
# sort vertices by their value in the second eigenvector
secondEigenvector = eigenvectors[:, 1]
sortedVertexIndices = secondEigenvector.argsort()
# compute the quality of a cut at index j in the sorted eigenvector
def cutQuality(j):
...
return crossEdges / min(leftEdges, rightEdges)
bestCutIndex = min(range(n), key=cutQuality)
leftHalf, rightHalf = sortedVertexIndices[:bestCutIndex], sortedVertexIndices[bestCutIndex:]
return list(sorted(leftHalf)), list(sorted(rightHalf))
If we apply this to a graph constructed with two halves that have a random 0.5 probability of an edge in each half, and only a 0.1 probability of an edge crossing the two halves, this program can find the two halves.
if __name__ == "__main__":
example = numpy.zeros((100, 100))
for i in range(100):
for j in range(100):
if i == j:
continue
if (i < 50 and j < 50) or (i ≥ 50 and j ≥ 50):
if random.random() < 0.5:
example[i, j] = 1
else:
if random.random() < 0.1:
example[i, j] = 1
theBestCut = bestCut(example)
print(theBestCut)
Running this gives:
([50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 88])
You’ll notice it only gets one vertex wrong, the 88 that shows up in the wrong half. An occasional error is expected since we’re adding edges randomly.
Finally, here’s a chart that shows how well the sparse-cut algorithm performs as that 0.5 interior edge rate goes down to 0.1 (cf sparsest_cut_test.py):

The quality of the cutting algorithm as the interior edge rate (horizontal axis) goes from 0.1 up to 0.5. A score (vertical-axis) of 2.0 is perfect accuracy, and a score of 1.0 is equivalently good to random guessing.
So you see that the quality really starts to degrade when the cross-edge rate is roughly half the interior-edge rate.
Further Reading
Fan Chung’s book Spectral Graph Theory is the bible for this field. You can find a revised manuscript on her website, or google to find many links to the original edition (with errata). Note in particular that her book generalizes the definitions in this post to work with weights on the edges of the graph. Which is good.
I also like these notes of Luca Trevisan because he draws out the connections between spectral graph theory and algorithms and CS theory.

Guest post, “What’s up with graph Laplacians?” | Math ∩ Programming
Nice post!
There seem to be a typo in the declaration of normalized laplacian’s matrix form:
\mathscr{L} = D^{-1/2}LD^{1/2}, should be \mathscr{L} = D^{-1/2}LD^{-1/2}.
LikeLiked by 1 person
Ah good eye, thanks!
LikeLike
Can you please help me in understanding if \lambda_1 > 0 if and only if G is connected. More specifically in the proof that you have given, I couldn’t appreciate the statement “This implies all x(u) – x(v) = 0 for every edge, but there is a path connecting any two pair of vertices, so all x(u) are equal”. What does this last statement really means?
LikeLike
A Spectral Analysis of Moore Graphs | Math ∩ Programming